See how automated optimization increases ResNet50 performance by 1.77x
One of the first thoughts that comes to mind about deep learning and AI is the hope that someday we might be able to develop cognition in computers, that our creations would be able to think on their own and reason at higher levels like we humans do. The inspiring achievements of AI we keep hearing about on a daily basis are powered by leapfrog advances in hardware and software in the past decades. Just since the millennia, CPU transistor count has increased from millions to billions, and specialized architectures that address the needs of AI and deep learning have emerged from industry giants such as Intel, NVidia, Google, and others.
Even with all these advances, realistic modern AI workloads have heavy performance demands on the system. One of the ways to improve performance is distributed execution, and deep learning frameworks such as TensorFlow support this natively. In TensorFlow, it is possible to distribute the workload among cores or even among different servers. TensorFlow allows users to fine-tune how workloads are parallelized by optimizing several parameters of the framework. While these parameters are indeed helpful in increasing the performance, they add yet another level of complexity to the already challenging task of data scientists, which is to develop and optimize the models themselves. The question is, can we relieve data scientists from the need to understand their specific underlying infrastructure and from the need to optimize the performance of their models?
Concertio’s Optimizer Studio was able to leverage the tunables of TensorFlow and Intel Xeon Scalable Processors to further accelerate deep-learning workloads. Optimizer Studio is able to relieve engineers from the task of finding optimal system settings, as it achieves at least comparable performance to manual tuning – but without the manual effort.
Our friends from Intel decided to check exactly that using three popular deep learning models based on Intel-optimized TensorFlow and Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN). Intel® MKL-DNN is open source and available on GitHub. The goal was to see whether their throughput can be improved automatically using our Optimizer Studio tool.
The first model, ResNet50, is a variant of Deep Residual Networks, ResNet is the deep convolutional neural network by Microsoft that won ILSRVC 2015. The second model, GNMT(Google’s Neural Machine Translation System) uses a neural network to make Google translate more effective and address many of the issues of a simple NMTs. The third model, DeepSpeech, is an open-source speech-to-text engine, implemented in TensorFlow. All these models are quite popular among deep learning community.
TensorFlow implementations of these models were compiled using Intel’s MKLDNN deep neural network library to accelerate computations on Intel-based systems. This was done to leverage the substantial amount of work that has been done on optimizing TensorFlow for Intel architectures, as described in this Intel documentation page. Engineers from Intel used Optimizer Studio to tune both TensorFlow tunables as well as system tunables.
TensorFlow Parallelism Tunables
The TensorFlow framework defines several tunable parameters, among them intra_op and inter_op. Optimizing these parameters can greatly accelerate throughput, but like many tunables there’s a tradeoff: higher values increase parallelism but also magnify the contention on shared resources such as the main memory and on-chip caches. At some point, the benefit of increased parallelism is outweighed by the slowdown due to the increased contention. There’s a middle ground, but the optimal values of the parallelism tunables are usually not easy to find without extensive experimentation. The inter_op and intra_op tunables are explained in the table below:
|
inter_op |
TensorFlow works on the basis of computational graphs. When TensorFlow encounters several independent branches that emerge from the same layer, it will attempt to run each independent branch in parallel using a thread pool with inter_op_parallelism_thread threads. |
|
intra_op |
Some operations within branches can also be parallelized. Convolution in a neural network is one example, where a kernel is “slided” over the feature map, and all the operations are independent. Another example is matrix multiplication, where independent multiplications can be done in parallel and later added. TensorFlow allocates a pool of intra_op_parallelism_thread threads for these purposes. |
Configuring Optimizer Studio for optimizing these parameters was simple, using the following configuration file:
domain:
common:
knobs:
inter_op:
options_script: seq 1 1 28
intra_op:
options_script: seq 10 2 56
metrics:
shell.my_target:
sample_script: cat /tmp/result.txt
aggregated: false
include_metrics: [shell.my_target]
plugins: [libshellplugin.so]
target: shell.my_target:max
Optimizer Studio was configured to search for the near-optimal configuration of inter_op and intra_op, where inter_op could be in the range of 1..28, and intra_op could be any even number from 10 to 56. These ranges represent 672 possible configurations, and it was not desirable to check every single one of them.
Optimizer Studio was further configured to run in synchronous mode, where it runs workloads iteratively with different configuration options, and then reports the best configuration it has found. At each iteration, a script that runs the task was invoked by Optimizer Studio, which passes the inter_op and intra_op parameters as environment variables. After running a few batches, the script parses the textual result and writes the performance metric into a temporary file /tmp/result.txt. Later, this file is read by Optimizer Studio to determine the performance of the evaluated configuration.
This optimization was applied to ResNet50 using this workload script:
LD_LIBRARY_PATH=../gcc6.3/lib64 numactl --membind=0 --cpunodebind=0 \
python ./scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --mkl=True \
--forward_only=True --num_batches=100 --kmp_blocktime=0 \
--num_warmup_batches=0 --num_inter_threads=${inter_op} \
--distortions=False --optimizer=sgd --batch_size=64 \
--num_intra_threads=${intra_op} --data_format=NCHW \
--num_omp_threads=${intra_op} --model=resnet50 | \
grep "total images/sec" | cut -d':' -f 2 > /tmp/result.txt
The optimization was done on an Intel(R) Xeon(R) Platinum 8180 with 384GB RAM.
The output of the run was as follows:
Concertio Optimizer Studio version 1.12
Running on CentOS7
Starting service ...
Optimizing ./run-concertio-workload.sh
Sampling mode: sync
Optimization target: shell.my_target:max
Optimization time: 02:24:42
Progress: 100%
Best known knob settings so far:
intra_op: 28
inter_op: 2
Anticipated improvement: 77.32%
No. of knobs: 2
Configurations explored/total: 78/672
Samples taken: 163
Settings written to: /tmp/studio-settings.sh
The performance during the optimization varied as shown in the plot below:
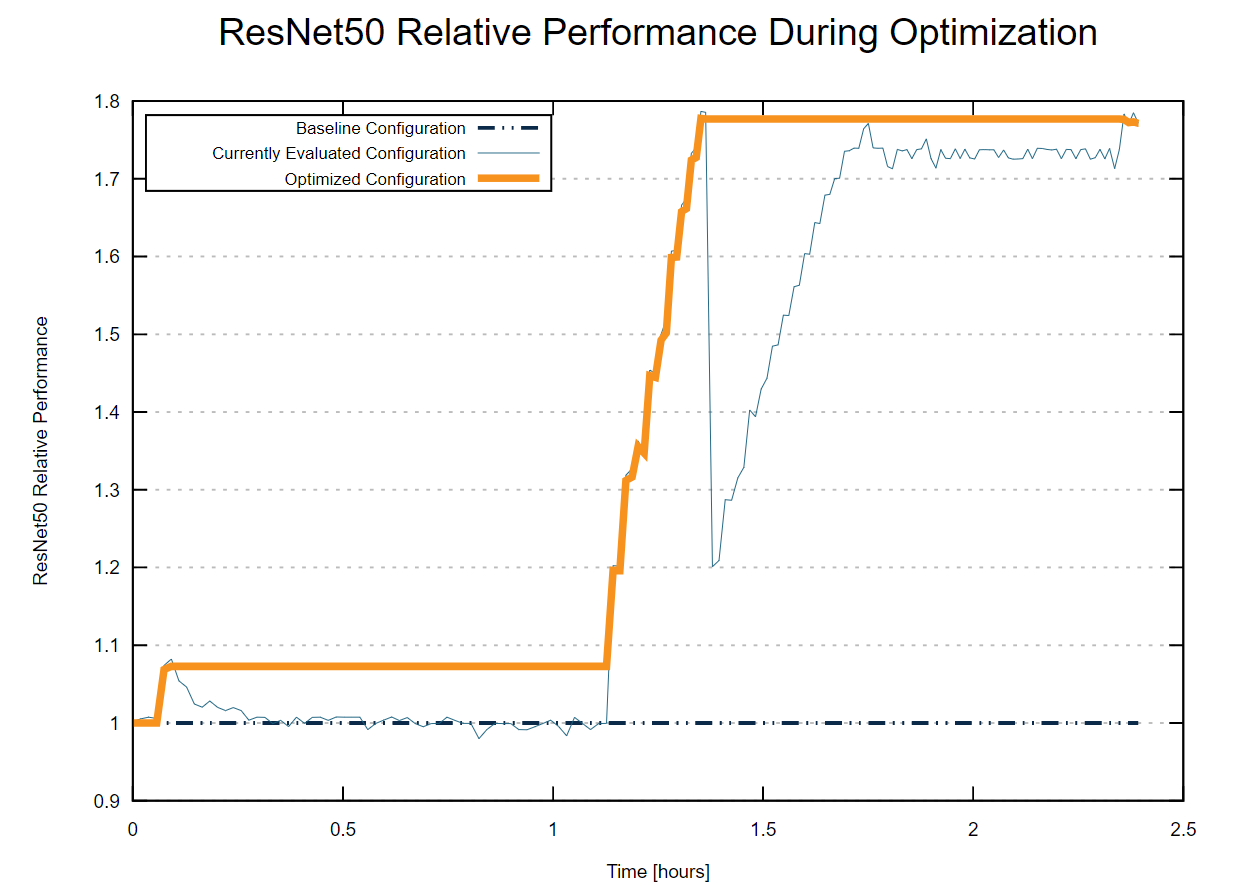
After two hours and eight minutes, Optimizer Studio found that the optimal values are intra_op=28 and inter_op=2. Using these values, while also setting the number of OMP threads to be as the number of intra_op threads, yielded 1.77x speedup over baseline. This was achieved automatically without any manual effort, and achieved comparable speedup to manual tuning by Intel’s engineers. What took 10’s of hours of manual labour was now done automatically in just 2 hours.
The inter_op and intra_op values control model level parallelism and data parallelism. The optimal setting of these parameters depend on the number of hardware threads as well as the availability of operations to run in parallel. Though one can know the number of hardware threads, it is difficult to guess the number of operations available for parallel execution. The cross product of the two parameters further increases the sample space making manual tuning tedious and hard to predict.
Beyond TensorFlow Tunables
GNMT and DeepSpeech were then evaluated to see whether optimized OS and CPU settings can yield further performance gains following manual optimization of their TensorFlow tunables. Optimizer Studio was used again for this task – it evaluated 173 and 156 different configurations out of the 9.13e17 possible configurations on the testing platform, and discovered settings that improve the performance by 8.3% and 8% respectively.
The configuration of the on-chip cache prefetchers had a big impact on the attained speedup. When we evaluated the logs, we noticed that the server was running with its L2 hardware prefetcher disabled before the optimization started. Optimizer Studio was able to find that the default of enabling the L2 hardware prefetcher actually performs better for the tested benchmarks. In addition to the prefetchers, the uncore frequency and the scheduling wakeup granularity of the kernel were also impactful and were optimized to better performing values.
Dr. Arjun Bansal, Vice President of AI Software and Research at Intel summarizes the experiments: “Concertio’s Optimizer Studio was able to leverage the tunables of TensorFlow and Intel Xeon Scalable Processors to further accelerate deep-learning workloads. Optimizer Studio is able to relieve engineers from the task of finding optimal system settings, as it achieves at least comparable performance to manual tuning – but without the manual effort.”
What this means for model training
Training realistic machine learning models incurs high infrastructure and engineering costs. While optimized systems can yield faster training times and require less infrastructure, it is usually out of scope for data scientists. Optimizer Studio can bridge this gap and allow data scientists to focus on optimizing the model accuracy, instead of on optimizing the infrastructure.
We thank Dr. Jayaram Bobba, Srinivasan Narayanamoorthy, Mahmoud Abuzaina, and Vivek Rane for their contributions and for putting together this experiment. Intel and Xeon are registered trademarks of Intel and/or its affiliates.
Disclaimers
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.
Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit: www.intel.com/benchmarks.
The configuration used in this experiment:
|
CPU |
Model Name: Intel(R) Xeon(R) Platinum 8180 @ 2.50GHz |
| Memory | 376GB (12 x 32GB) 24 slots, 12 occupied 2666 MHz |
| Disks | Intel RS3WC080 x 3 (800GB, 1.6TB, 6TB) |
| BIOS | SE5C620.86B.00.01.0004.071220170215 |
| OS | Centos Linux 7.4.1708 (Core) Kernel 3.10.0-693.11.6.el7.x86_64 |
|
TensorFlow |
GitHub source code |
| Intel® MKL-DNN | Version 0.14 https://github.com/intel/mkl-dnn/archive/v0.14.tar.gz |
Performance results are based on testing by Intel as of August 14, 2018, and may not reflect all publicly available security updates. See configuration disclosure for details. No component or product can be absolutely secure.
Optimization Notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.