In large organizations (OEMs), running SPEC-CPU benchmarks is a time-consuming affair. Multiple SKUs and various different chips lead to a bunch of different combinations to figure out for the best possible scores. The method to run the SPEC-CPU benchmarks is usually iterative. Different vendors and manufacturers run the benchmark and submit their respective results to the Standard Performance Evaluation Corporation (SPEC).
Typically, an engineer would be tasked to figure out the best combination of flags to achieve the highest scores. The engineer would contact the chip manufacturer and get the recommended “best flags”. On top of this, the engineer would then change a few parameters depending on the SKU that is under test. After this, it is more or less trial and error. There are so many subsystems that might have an effect on the final score, such as:
- Which OS distribution and kernel to work with?
- Which compiler to use?
- Which compiler flags to use?
- How should the OS be configured?
- How should the BIOS be configured?
- Which libraries (for example, a memory allocation library) should be used?
- And so on…
Optimizing these benchmarks is not only time-consuming, but it is usually also time-sensitive, as marketing needs those scores for the product launch. Although some of the tuning activities can be performed before the actual hardware arrives, the crux of the work needs to be done on the metal. With all of these constraints, as well as the sheer number of configuration options, it is no wonder why we see many companies turning to machine learning to help in this process. An automated approach to tuning benchmarks potentially achieves three important goals:
- Higher scores
- Shorter time-to-market
- Lower human effort (cost)
Tuning SPEC-CPU benchmarks is tough and competitive. In this blog, we show how we evaluate one benchmark out of the SPEC-CPU benchmark suite and make it faster than the best published result, with minimal expertise and human effort.
The 525.x264_r benchmark
If you’re familiar with 525.x264_r benchmark, feel free to skip this section and proceed to the optimization part. Otherwise, below is a high-level description of this benchmark that belongs to the SPECrate 2017 Integer benchmark suite:
x264 is an open source application library for encoding video streams into H.264/MPEG-4 AVC format. It’s maintained and distributed by the VideoLan project. The 525.x264_r source code is obtained from VideoLan, and it uses the Blender Open Movie Project’s “Big Buck Bunny“. For further information please refer to 525.x264_r SPEC CPU®2017 Benchmark Description.
Tuning AOCC compiler flags for 525.x264_r benchmark using Optimizer Studio
For this experiment, we used the AMD Optimizing C/C++ Compiler (AOCC) to build the 525.x264_r benchmark on AMD bare-metal server (AMD EPYC 7402P). The AMD Optimizing C/C++ Compiler (AOCC) is a high performance compiler from AMD targeting 32-bit and 64-bit Linux platforms. It is a proprietary fork of LLVM + Clang with various additional patches to improve performance for AMD’s Zen microarchitecture in Epyc and Ryzen microprocessors.
Concertio’s Optimizer Studio uses advanced search algorithms to explore large parameter spaces with a reasonably short amount of time. The entire workflow is automated, hence it only requires minimum effort to prepare the required scripts. Once we have the automation scripts ready, we start Optimizer Studio and wait for the run to finish. At the end of the run, Optimizer Studio reports the best configuration it found. We chose to focus on mining the compiler flags used for compiling the benchmark.
When it comes to choosing the right compiler flags, there are several challenges that are often overlooked by developers, yet have significant impact on the performance of the resulting binary or application. First off, there are just too many compiler options that, unless you’re a compiler expert, you might not even know they exist. The second and most difficult challenge is finding the optimal flags for compiling every application by performing manual or exhaustive search, as the number of possible configurations easily exceeds the number of atoms in the universe (10^300 >> 10^80).
Optimizer addresses both challenges. For the first challenge, it is no longer required to be a compiler expert and know about all of the possible compiler flags since the flags (and 1000’s of other tunable definitions) are shipped with Optimizer Studio out-of-the-box. All that is required is to import the relevant embedded compiler flag definitions:
import:
optimizer.compilers.aocc:As for the second challenge, Optimizer Studio uses advanced algorithms to search for the best configuration. This has three benefits:
- Optimizer Studio’s evolution search algorithm usually outperforms manual search by domain experts
- The search process is completely automated, so no human effort is required
- The time-to-market (time to deliver benchmark results) is significantly shortened as Optimizer Studio is able to find the best results quicker than manual tuning, and human errors are eliminated due to automation
Experiment Setup
The experiment is performed on Equinix bare-metal server (c3.medium.x86), with 1x AMD EPYC 7402P 24-Core Processor @ 2.8GHz and 64GB RAM.
- OS: CentOS8
- Compiler: AOCC C/C++/Fortran Version 2.0.0
- Memory allocator: jemalloc memory allocator library v5.2.0
Our setup is similar to the setup of Dell’s report for SPEC CPU®2017 Integer Rate. However, we did not configure the settings under Platform Notes since we didn’t have physical access to the server. We measured Dell’s peak settings and achieved 220 seconds, compared with the 216 seconds that were officially published, the difference might be attributed to the BIOS settings that we did not apply.
Optimizer Studio uses advanced algorithms to explore the parameter space and runs a user-provided workload script iteratively, passing the selected flag combinations to the workload script on every iteration.
The workload script cleans the build files, builds the benchmark with the selected flags and runs the benchmark. We use the configuration file that is included with the installation of SPEC-CPU (Example-aocc-linux-x86.cfg). The workload script parses this configuration and updates the compilation flags on every iteration of the optimization.
525.x264_r tuning results
We configured Optimizer Studio to start from the peak flags reported by Dell Inc, and let it run to search for flags that could beat the performance of Dell’s peak flags. Optimizer Studio currently supports 73 different AOCC flags, representing 2.2*10^33 possible flag combinations. Each configuration was sampled twice and the mean of the samples was chosen as a point estimator.
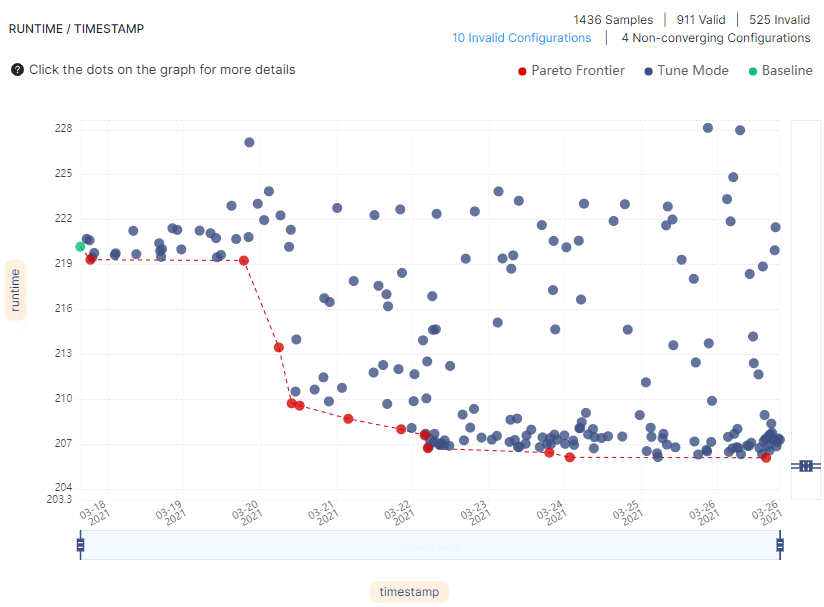
Most of the performance gains were attained early on: 70 hours into the run, the speedup was already 5.1%, and in 110 hours the speedup was 6.52%. Eventually, after 9 days, the speedup was 6.84% (206 seconds). In order to speed up the optimization process, we re-ran it using Optimizer Studio’s workload timeout feature set for 10 minutes. In this case, the optimization process ended after 3 days (reduction from 9 days), a result of 207 seconds was achieved within an hour and a half (see below), and a result of 206 seconds was achieved after one day. It is possible to further shorten the optimization process by running on numerous servers in parallel using Optimizer Studio’s parallel execution feature.
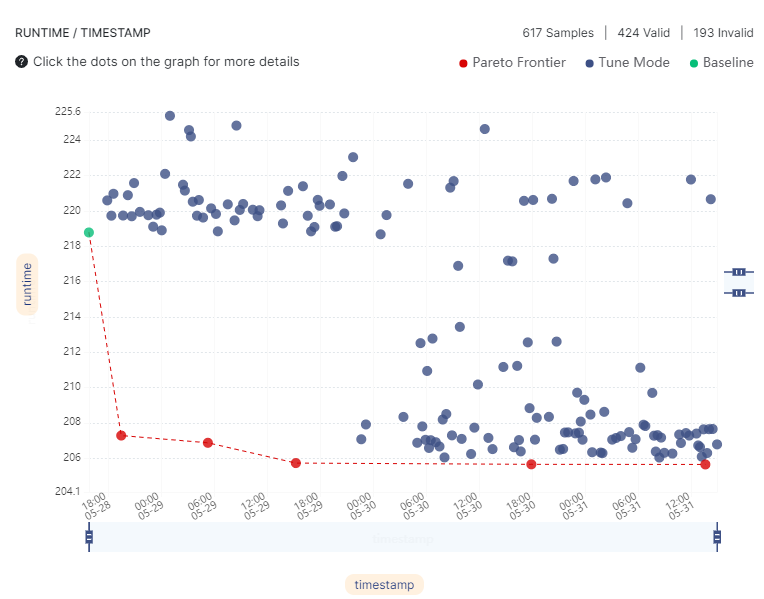
Refinement and invalid search algorithms
Optimizer Studio features a refinement algorithm, which prunes flags that are not influential performance-wise from the optimal found configuration. It produced the following minimal changes from Dell’s peak settings:
New flags: -fno-autolink -funroll-loops
Removed flags: -flv-function-specialization -mllvm -function-specialize
Another algorithm employed by Optimizer Studio is “invalid search”. In cases where compilation fails, or if the SPEC run produces an invalid result, Optimizer Studio will explore the flags and get to the bottom of which combination of flags caused the run to fail. Such combinations are then skipped, greatly shortening the time to finish the optimization process. In subsequent runs of the same experiment, this information is reused to save time.
How to win in benchmarks using machine learning
Optimizer Studio was able to outperform the published result of a SPEC-CPU benchmark by 7%, without needing any performance engineering skills. All that was required was to build the automation scripts, examples of which are provided with Optimizer Studio. Setting up the experiment took only a few hours of scripting work, and then, the experiment continued unattended. The higher performance, shorter time to market, and lower engineering costs, are among the reasons why we see more and more companies leverage machine learning in order to win with better benchmark results.